
Yaoshiang Ho
I love building innovative products that people want. I've worked at early stage startups, Google & Amazon, and digital media companies, always solving the zero-to-one challenge.
I started off as a backend software engineer, then worked in value capture roles. To help scale organizations, I picked up experience in people management, finance, and analytics.I combined all these learnings in the past 10 years in entrepreneural ventures, starting with just an idea, validating it with customers, building product, and bringing it to market.
I'm the cofounder of Masterful AI, a deep learning / generative ai startup where I've been gone deep into engineering, research, go-to-market, and product.
Featured Experience
Masterful AI
Cofounder
2019 - present
I cofounded Masterful AI with two old friends. I wrote POCs for our initial product ideas including detecting adversarial AI attacks and creating synthetic data using Generative Adversarial Networks and Autoencoders. We settled on an AutoML platform for CV. I ended up researching and programming our augmentation meta-learning algorithms and SOTA semi-supervised learning algorithms (docs). We also created SceneCraft, a generative AI tool for small Shopify merchants to create more and better social media posts.
Stealth Blockchain Startup
Product
2017-2019
I got excited about blockchain and joined startup backed by Lightspeed and Accel. Although I'm no longer involved in blockchain, this was the catalyst to rediscover how much I enjoy programming.
Lionsgate
SVP Business Operations
2014 - 2018
I was the first hire for the streaming group. I wrote business plans and financial models, oversaw technical buildout, and closed distribution deals. Three of the products we launched found product-market fit and are still available today. I also led our Series B investment Tubi TV (15x return). I was an active member of the board, helping the founders identify and prevent existential risks to the business.
Business Development Principle (L7)
2010 - 2013
Strategic partnerships I struck include: credit card processors processors for Google Attribution, proprietary data providers for Google Knowledge Graphs, construction companies for the buildout of Project Link and content companies for YouTube.
Amazon
Product Manager Intern
2005
I was the first product manager for what was then called Amazon Unbox (now Amazon Video). I was amazed how informal the processes were at Amazon - it really was focused outcomes, rather than process. I particularly like the values of an unreasonable customer obsession - as that Steve Jobs video shows, focusing on the customer is the best way to think about product and business decisions. And "disagree and commit": still a controversial approach to to staying aligned and trying new ideas.
Upwork
Software Engineer / Technical Product Manager
2001-2004
I worked on our backend server built in Java. The fun stuff was working on managing our proprietary multi-threaded architecture and optimizing physical query plans. The boring stuff was implementing business logic.
Projects
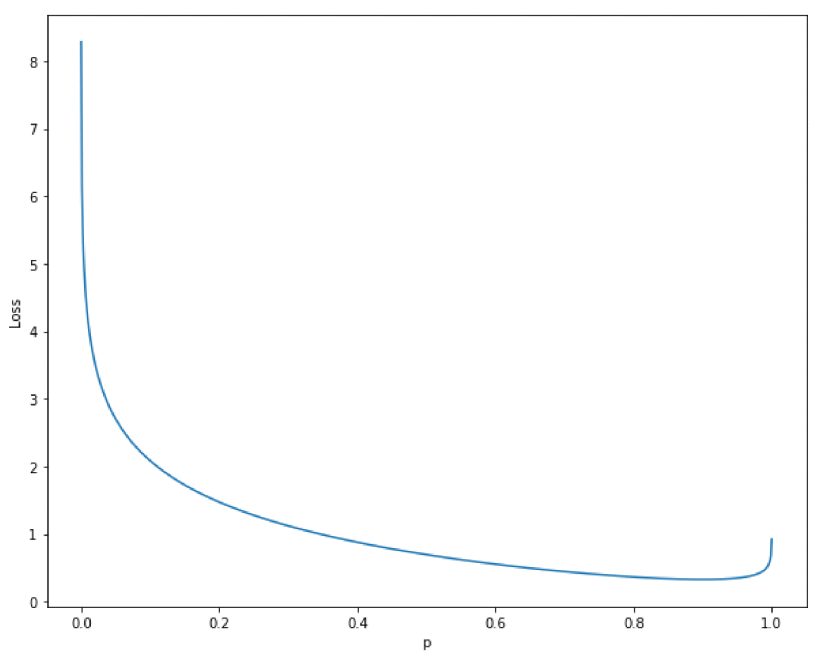
The Real-World-Weight Cross-Entropy Loss Function
2019
For single-label, multiclass classification problems (like ImageNet), weighting predictions simply shifts the balance between FPs and FNs. My research extended this to be conditional on the ground truth. This can reduce mistakes such as confusing one disease for another. Published by IEEE Access.

The Human Visual System and Adversarial AI
2020 Preprint
Adversarial AI attempts to fool AI models by tweaking pixels in a way that is inperceptible to humans. This paper explored hiding the tweaked pixels in high entropy areas of an iamge, where the human eye is less likely to notice them. Preprint at Arxiv.

Weather plugin for ChatGPT.
Live
I was curious how Open AI designed their Plug-In API so I put together a weather plugin. Installation instrunctions at weatherplugin.net.
This was also a chance to get up to speed on launching a JSON service on AWS Lambda.
The concept of plugins raises two strategic questions for me. First, will ChatGPT be a backend service, powering an LLM feature of existing products? Or will ChatGPT become a new destination and gatekeeper, like the Apple App Store and Google.com? If the latter, there's more opportunity for disruptive startups.

Clustered Augmentation Policy
2022 Technical Report
RandAug innovated on AutoAug by reducing the search space to ~100. But I felt like RA simply pre-picked policy options that fit ImageNet well. I sought a policy that could truly adapt while further reducign the search space to ~10. I took the concept of Frechet Inception Distance to cluster augmentations based on how much they perturbed the loss value. Arxiv.

NST0: Color Matching Images
Positive Results, Unpublished
After reading the Neural Style Transfer paper by Xun Huang (to understand the StyleGAN paper), I realized that I could apply the same concepts to transfer color palettes between images by thinking of the RGB channels as the most basic concept of "style". Since there were no learned filters / kernels, I called this "Neural Style Transfer Zero" or "NST0". The NST0 technique applies the logit function to transform the [0.0, 1.0] unit interval pixel range into the unbounded real number space, performs z-score matching, and finally uses a sigmoid function to return to the unit interval pixel range. It's visually superior to z-score matching of the raw RGB channels, because NST0 never clips pixel ranges. It also avoids "kinks" in the color distributions of QQ matching. I'm still working on a paper, but you can try the tool in my tools section: NST0 Tool. This was also a chance to learn how to deploy a model that runs in the browser via onnx runtime (ORT for Web).

Embedding based detection
Hypothesized, unpublished
Detection is one of the least "deep learning" feeling computer vision tasks, at least in the way current detection heads are implemented. A model is forced to predict [300] objects, in a specific order, leading to duplicate predictions and kludges like non-max supression (NMS). I hypothesize that instead of forcing an ordering, a model should be allowed to present predictions in any order, but also output an embedding. The loss function would collapse predictions with close embeddings, and correlate y_true and y_pred based purely on bounding box IoU, then calculating traditional crossentropy and smooth L1 loss.
Layerwise Weight Decay
Positive Results, Unpublished
Since learning rate adapts by layer in LARS/LAMB, I figure weight decay should as well. My goal is to prove that a single weight decay hyperparameter is inferior to a set of layerwise hyperparameters. I have achieved positive results with a simple algorithm, but I think I can get 1% improvement with a bit more sophistication. My reasoning is that, if we think of weight decay as a form of Maxium A Posteriori (MAP) estimation, where "weight decay" is basically using a zero-centered prior, then you'd want to apply this prior more strongly in layers that you know are more likely to overfit. In "Unsupervised Representation Learning by Predicting Image Rotations" by Spyros Gidaris, Praveer Singh, Nikos Komodakis indicate that latter layers are more overfit to the task, whereas early layer are likely underfit. Therefore, I'd generally assume we need more weight decay in latter layers of the model. Fun Note: I initially got dramatic results - 2% on Efficient v2 B0! But I figured out that the pretrained weights in were incorrect in the original PR. The authors (and reviewers) forgot to verify top-1 accuracy on Imagenet Validation, but went ahead and took the accuracies from the paper and included them in the docs. TF ~2.9 fixed this bug.
LLM compression techniques applied to CV.
Not started
Can LoRa and NF4 be applied to classic CV models like ResNet-50 to reduce inference cost & time while maintaining accuracy?